第一章:程序之道
第一个程序
|
|
值和类型
| 值 | 类型 | |
|---|---|---|
| 2 | 整型数(integer) | |
| 42.0 | 浮点数(floating) | |
| ‘Hello,Word!’ | 字符串(string) |
不确定某个值的类型是什么时,解释器可以告诉你:
第二章:变量、表达式和语句
变量名
可以包括字母和数字,但是不能以数字开头。下划线_可以出现在变量名中。
class 是Python的关键字之一。 解释器使用关键字识别程序的结构,它们不能被用作变量名。Python3有以下关键词:
| False | None | True | and | as | assert | break |
|---|---|---|---|---|---|---|
| class | continue | def | del | elif | else | except |
| finally | for | from | global | if | import | in |
| is | lambda | nonlocal | not | or | pass | raise |
| return | try | while | with | yield | – | – |
脚本模式
到目前为止,我们都是在交互模式(interactive mode)下运行Python,即直接与解释器进行交互。另一种方法是将代码保存到一个被称为脚本(script)的文件里,然后以脚本模式(script mode)运行解释器并执行脚本(.py)。
字符串运算
加号运算符 + 可用于字符串拼接(string concatenation),也就是将字符串首尾相连起来。
乘法运算符 * 也可应用于字符串;它执行重复运算。 例如,'Spam' * 3 的结果是 ‘SpamSpamSpam’ 。
第三章:函数
数学函数
Python中有一个数学模块(math),提供了大部分常用的数学函数。模块(module)指的是一个含有相关函数的文件。
在使用模块之前,我们需要通过导入语句(import statement)导入该模块:
组合
编程语言的最有用特征之一,是能够将小块构建材料(building blocks)组合(compose)在一起。 例如,函数的实参可以是任意类型的表达式,包括算术运算符:
术语表
| 名词 | 定义 |
|---|---|
| 形参(parameters) | 函数内部用于指向被传作实参的值的名字 |
| 实参(argument) | 函数调用时传给函数的值。这个值被赋给函数中相对应的形参 |
| 局部变量(local variable) | 函数内部定义的变量。局部变量只能在函数内部使用 |
| 模块(module) | 包含了一组相关函数及其他定义的的文件 |
| 导入语句(import statement) | 读取一个模块文件,并创建一个模块对象的语句 |
| 回溯(traceback) | 当出现异常时,解释器打印出的出错时正在执行的函数列表 |
第四章:案例研究:接口设计
在cmd下运行Python脚本
方法1
- 新建个.py文件,写上Python代码,每个.py文件都是可以认为是一个Python模块
- 打开Windows的cmd,并且切换(cd)到对应的python脚本所在目录
- 输入你的Python脚本,即.py文件的完整的文件名
- 可以利用Tab键,然后会自动显示出当前目录的文件,多次按Tab键,会在多个文件之间切换。
- 然后输入回车,即可运行对应的Python脚本
方法2
Python D\:Python27\mypy\文件名.py
如何使用Python的交互式的shell(command line模式和GUI模式)
Python有个shell,提供一个Python运行环境。即写一行代码,就可以立刻被运行,然后方便查看到结果。而Python的Shell,在Windows环境下,又分两种:Python (command line) 和IDLE (Python GUI),两者都比较适合偶尔要测试少量的Python代码的情况下去使用,而不适合长期的开发Python。
如果要调用另一个python脚本用 import 文件名(不包括.py),这个脚本要在PYTHONPATH的路径下。
- 在python里建一个文件夹,专门存放你的模块,例如:在python.exe路径下建了一个名为mypy的文件夹
- 设置一个环境变量PYTHONPATH,以便Python解释器找到相应模块
- 步骤:计算机>>属性>>高级系统设置>>环境变量>>系统变量>>新建>>
变量名:PYTHONPATH; 变量值:D\:Python27\mypy - 执行以下代码,mypy也会同其他系统path一起显示出来!12import syssys.path
什么是Python的IDE
开发Python过程中,写Python代码,调试Python代码,查找相关的函数的解释等等操作,如果都是基于前面介绍的,用Notepad++等编辑器去编辑Python代码,写完代码了,再切换到windows的cmd中去运行,往往觉得很麻烦。尤其是大型项目的话,可能就更加显得不那么高效;以及对应的需要一些额外的功能,比如调试复杂的Python代码,需要一点点跟踪调试,找到错误的根本原因等等。
Python发展到现在,已经有了很多第三方的,别人开发的,可以用于或者专门用于Python开发的一些集成开发环境,即Python的IDE。
术语表:
| 名词 | 定义 |
|---|---|
| 封装(encapsulation) | 将一个语句序列转换成函数定义的过程 |
| 泛化(generalization) | 使用某种可以算是比较通用的东西(像变量和形参),替代某些没必要那么具体的东西(像一个数字)的过程 |
| 关键字实参(keyword argument) | 包括了形参名称作为“关键字”的实参 |
| 接口(interface) | 对如何使用一个函数的描述,包括函数名、参数说明和返回值 |
| 重构(refactoring) | 修改一个正常运行的函数,改善函数接口及其他方面代码质量的过程 |
第五章:条件和递归
递归
一个调用它自己的函数是递归的(recursive); 这个过程被称作递归(recursion),例如:
堆栈图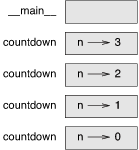
- 在计算机中,函数调用是通过
栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。 - 每当一个函数被调用时,Python生成一个新的
栈帧,用于保存函数的局部变量和形参。通常,堆栈的顶部是__main__栈帧。 因为我们在__main__中没有创建任何变量,也没有传递任何实参给它, 所以它是空的。 - 对于形参n,四个
countdown栈帧有不同的值。 n=0的栈底,被称作基础情形(base case)。 它不再进行递归调用了,所以没有更多的栈帧了。
举个栗子:阶乘 n!=n(n−1)!
堆栈图
该图中的返回值被描绘为不断被传回到栈顶。 在每个栈帧中,返回值就是结果值,即是 n 和 recurse 的乘积。
再举个栗子:斐波那契数列
除了阶乘以外,使用递归定义的最常见数学函数是 fibonacci
fibonacci(0) = 0
fibonacci(1) = 1
fibonacci(n) = fibonacci(n−1) + fibonacci(n−2)
如果我们将 1.5 作为参数调用阶乘函数会怎样?
看上去像是一个无限循环。函数的基础情形是 n == 0 。 但是如果 n 不是一个整型数呢,我们会错过基础情形,永远递归下去。在第一次递归调用中,n 的值是 0.5 。下一次,是 -0.5 。自此它会越来越小,但永远不会是 0 。
我们可以使用内建函数 isinstance 来验证实参的类型。确保该实参是正数:
此程序演示了一个有时被称作 监护人(guardian) 的模式。 前两个条件扮演监护人的角色,避免接下来的代码使用引发错误的值。
术语表
| 名词 | 定义 |
|---|---|
| 临时变量(temporary variable) | 一个在复杂计算中用于存储过度值的变量 |
| 死代码(dead code) | 程序中永远无法执行的那部分代码,通常是因为其出现在一个返回语句之后 |
| 增量式开发(incremental development) | 一种程序开发计划,目的是通过一次增加及测试少量代码的方式,来避免长时间的调试 |
| 脚手架代码(scaffolding) | 程序开发中使用的代码,但并不是最终版本的一部分 |
| 监护人(guardian) | 一种编程模式,使用条件语句来检查并处理可能引发错误的情形 |
第七章:迭代
迭代,即重复运行某个代码块的能力。
- 之前已经接触了一种利用
递归进行迭代的方式; - 在简单的重复一节中,接触了另一种利用
for 循环进行迭代的方式。 - 在本章中,我们将讨论另外一种利用
while 语句实现迭代的方式。12345def countdown(n):while n > 0:print(n)n = n - 1print('Blastoff!')
while 语句
- 首先判断条件为真还是为假。
- 如果为假,退出 while 语句,然后执行接下来的语句;
- 如果条件为真,则运行 while 语句体,运行完再返回第一步;
- 这种形式的流程叫做
循环(loop),因为第三步后又循环回到了第一步。
break
有些时候循环执行到一半你才知道循环该结束了。这种情况下,你可以使用break语句来跳出循环。
调试
更多的代码意味着更高的出错概率,并且会有更多隐藏 bug 的地方。减少调试时间的一个方法就是 对分调试 。例如,如果程序有100行,你一次检查一行,就需要100步。
术语表
| 名词 | 定义 |
|---|---|
| 初始化(initialize) | 给后面将要更新的变量一个初始值的一种赋值方法 |
| 递增(increment) | 通过增加变量的值的方式更新变量(通常是加 1) |
| 递减(decrement) | 通过减少变量的值的方式来更新变量 |
| 迭代(iteration) | 利用递归或者循环的方式来重复执行代一组语句的过程 |
第八章:字符串
字符串是一个序列(sequence)
|
|
对于大多数人,’banana’ 的第一个字母是 b 而不是 a 。 但是对于计算机科学家,索引是从字符串起点开始的位移量 F(offset) ,第一个字母的位移量就是 0 。
字符串切片
字符串的一个片段被称作 切片(slice) 。 选择一个切片的操作类似于选择一个字符:
[n:m] 操作符返回从第n个字符到第m个字符的字符串片段,包括第一个,但是不包括最后一个

字符串是不可变的
|
|
出现此错误的原因是字符串是 不可变的(immutable) ,这意味着你不能改变一个已存在的字符串。
搜索
遍历一个序列并在找到寻找的东西时返回 —— 被称作 搜索(search) 。
循环和计数
下面的程序计算字母a在字符串中出现的次数:
字符串方法
字符串提供了可执行多种有用操作的 方法(method) 。方法和函数类似,接受实参并返回一个值,但是语法不同。 例如:upper,不过使用的不是函数语法 upper(word) , 而是方法的语法 word.upper() 。
点标记法的形式指出方法的名字: upper,以及应用该方法的字符串的名字: word 。空括号表明该方法 不接受实参。这被称作方法调用(invocation) ;在此例中,我们可以说是在 word 上调用 upper 。
事实上,有一个被称为 find 的字符串方法, 与我们之前写的函数极其相似:
in 运算符
单词 in 是一个布尔运算符
术语表
|对象(object)|变量可以引用的东西。现在你将对象和值等价使用|
|序列(sequence)|一个有序的值的集合,每个值通过一个整数索引标识|
|元素(item)|序列中的一个值|
|索引(index)|用来选择序列中元素(如字符串中的字符)的一个整数值。 在Python中,索引从0开始|
|切片(slice)|以索引范围指定的字符串片段|
|空字符串(empty string)|一个没有字符的字符串,长度为0,用两个引号表示|
|不可变 (immutable)|元素不能被改变的序列的性质|
|遍历(traversal)|对一个序列的所有元素进行迭代,对每一元素执行类似操作|
|搜索(search)|一种遍历模式,当找到搜索目标时就停止|
|方法调用(invocation)|执行一个方法的声明|
第十章:列表
列表是一个序列
在字符串中,每个值都是字符; 在列表中,值可以是任何数据类型。列表中的值称为 元素(element) ,有时也被称为 项(item) 。一个列表在另一个列表中,称为嵌套(nested)列表。
列表是可变的
和字符串不同的是,列表是可变的。当括号运算符出现在赋值语句的左边时,它就指向了列表中将被赋值的元素。
列表操作
|
|
第一个例子重复4次。第二个例子重复了那个列表3次。
列表切片
切片(slice) 运算符同样适用于对列表:
如果你省略第一个索引,切片将从列表头开始。如果你省略第二个索引,切片将会到列表尾结束。
切片运算符放在赋值语句的左边时,可以一次更新多个元素:
列表方法
append 添加一个新元素到列表的末端:
extend 将接受一个列表作为参数,并将其其中的所有元素添加至目标列表中:
sort 将列表中的元素从小到大进行排序:
映射、筛选和归并
删除元素
如果你知道元素的下标,你可以使用 pop :
如果你知道要删除的值(但是不知道其下标),你可以使用 remove :
列表和字符串
一个字符串是多个字符组成的序列,一个列表是多个值组成的序列。但是一个由字符组成的列表不同于字符串。
| Method | Code |
|---|---|
| list 字符串转换为字符的列表 |
>>> s = 'spam' >>> t = list(s) >>> t ['s', 'p', 'a', 'm'] |
| split 一个字符串分割成一些单词 |
>>> s = 'pining for the fjords'>>> t = s.split()>>> t['pining', 'for', 'the', 'fjords'] |
| delimiter 指定什么字符作为单词之间的分界线 |
>>> s = 'spam-spam-spam'>>> delimiter = '-'>>> t = s.split(delimiter)>>> t['spam', 'spam', 'spam'] |
| join 一个字符串方法,需要在一个分隔符上调用它,并传入一个列表作为参数 |
>>> t = ['pining', 'for', 'the', 'fjords']>>> delimiter = ' '>>> s = delimiter.join(t)>>> s'pining for the fjords' |
术语表
| 列表(list) | 多个值组成的序列 |
|---|---|
| 元素(element) | 列表(或序列)中的一个值,也称为项 |
| 嵌套列表(nested list) | 作为另一个列表的元素的列表 |
| 累加器(accumulator) | 循环中用于相加或累积出一个结果的变量 |
| 增量赋值语句(augmented assignment) | 一个使用类似 += 操作符来更新一个变量的值的语句 |
| 归并(reduce) | 遍历序列,将所有元素求和为一个值的处理模式 |
| 映射(map) | 遍历序列,对每个元素执行操作的处理模式 |
| 筛选(filter) | 遍历序列,选出满足一定标准的元素的处理模式 |
| 对象(object) | 变量可以指向的东西。一个对象有数据类型和值 |
| 相等(equivalent) | 有相同的值 |
| 相同(identical) | 是同一个对象(隐含着相等) |
| 引用(reference) | 一个变量和它的值之间的关联 |
| 别名使用 | 两个或者两个以上变量指向同一个对象的情况 |
| 分隔符(delimiter) | 一个用于指示字符串分割位置的字符或者字符串 |
第十一章:字典
字典即映射
字典包含了一个索引的集合,被称为键(keys) ,和一个值(values)的集合。 一个键对应一个值。这种一一对应的关联被称为 键值对(key-value pair), 有时也被称为 项(item)。
字典作为计数器集合
生成一个字典,将字符作为键,计数器作为相应的值。字母第一次出现时,你应该向字典中增加一项。 这之后,你应该递增一个已有项的值。
字典和列表
在字典中,列表可以作为值出现。但是不能是键,字典使用哈希表实现,这意味着键必须是 可哈希的(hashable)。
倒转字典的函数:
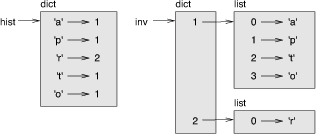
备忘录
fibonacci 函数,输入的实参越大,函数运行就需要越多时间。 而且运行时间增长得非常快。
要理解其原因,请看 fibonacci 的 调用图(call graph) :
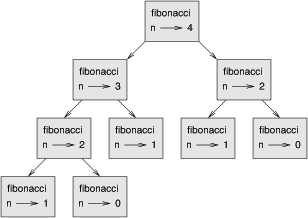
保存已经计算过的值,将它们存在一个字典中。存储之前计算过的值以便今后使用,它被称作 备忘录(memo) 。当 fibonacci 被调用时,它先检查 known 。 如果结果存在,则立即返回。 否则,它必须计算新的值,将其加入字典,并返回它。
全局变量
术语表
| 名词 | 定义 |
|---|---|
| 字典(dictionary) | 将键映射到对应值的映射 |
| 键值对(key-value pair)/项(item) | 键值之间映射关系的呈现形式 |
| 实现(implementation) | 执行计算的一种形式 |
| 哈希表(hashtable) | 用来实现Python字典的算法 |
| 哈希函数(hash function) | 哈希表用来计算键的位置的函数 |
| 可哈希的(hashable) | 具备哈希函数的类型。诸如整数、浮点数和字符串这样的不可变类型是可哈希的;诸如列表和字典这样的可变对象是不可哈希的 |
| 逆向查找(reverse lookup) | 接受一个值并返回一个或多个映射至该值的键的字典操作 |
| raise语句 | 专门印发异常的一个语句 |
| 调用图(call graph) | 绘出程序执行过程中创建的每个栈帧的调用图,其中的箭头从调用者指向被调用者 |
| 备忘录(memo) | 一个存储的计算值,避免之后进行不必要的计算 |
| 标记(flag) | 用于说明一个条件是否为真的布尔变量 |
| 声明(declaration) | 类似global这种告知解释器如何处理变量的语句 |
第十二章:元组
元组是不可变的
元组是一组值的序列,其中的值可以是任意类型。元组与列表非常相似。 二者不同之处在于元组的不可变性。
关系型运算符也适用于元组和其他序列:
元组赋值
|
|
元组作为返回值
内建函数 divmod 接受两个实参,返回包含两个值的元组:商和余数
可变长度参数元组
函数可以接受可变数量的参数。 以 * 开头的形参将输入的参数汇集到一个元组中。
与汇集相对的,是分散(scatter)。如果你有一个值序列,想将其作为多个参数传递给一个函数,你可以使用运算符 *。
列表和元组
zip 是一个内建函数,可以接受将两个或多个序列组,并返回一个元组列表,其中每个元组包含了各个序列中相对位置的一个元素。这个函数的名称来自名词拉链(zipper),后者将两片链齿连接拼合在一起。
如果需要遍历一个序列的元素以及其索引号,您可以使用内建函数 enumerate :
术语表
| 名词 | 定义 |
|---|---|
| 元组(tuple) | 一个由多个元素组成的不可变序列 |
| 元组赋值(tuple assignment) | 一种赋值方式,等号右侧为一个序列,等号左侧为一个变量组成的元组。右侧的表达式先求值,然后其元素被赋值给左侧元组中对应的变量 |
| 汇集(gather) | 组装可变长度实参元组的一种操作 |
| 分散(scatter) | 将一个序列变换成一个参数列表的操作 |
| zip 对象 | 使用内建函数 zip 所返回的结果;它是一个可以对元组序列进行迭代的对象 |
| 迭代器(iterator) | 一个可以对序列进行迭代的对象,但是并不提供列表操作符和方法 |
| 数据结构(data structure) | 一个由关联值组成的的数据集合,通常组织成列表、字典、元组等 |
| 形状错误(shape error) | 由于某个值的形状出错,而导致的错误;即拥有错误的类型或大小 |
第十三章:案例研究:数据结构选择
词频分析
随机数
伪随机数不是真正的随机数,因为它们由一个确定性的计算生成
| randdom模块 | 参数解释 |
|---|---|
randomx = random.random() |
返回一个 0.0 到 1.0 之间的随机浮点数(包括 0.0 ,但是不包括 1.0 ) |
randintrandom.randint(5, 10) |
接受参数 low 和 high , 返回一个 low 和 high 之间的整数(两个都包括) |
choicerandom.choice(t) |
从一个序列t中随机选择一个元素 |
待续
第十四章:文件
读取和写入
要写入一个文件,你必须在打开文件时设置第二个参数来为 w 模式:
如果该文件已经存在,那么用写入模式打开它将会清空原来的数据并从新开始。
完成文件写入后,你应该关闭文件。如果你不关闭这个文件,程序结束时它才会关闭。
格式化运算符
write的参数必须是字符串,所以如果想要在文件中写入其它值,我们需要先将它们转换为字符串。使用 格式化运算符(format operator) ,即 % 。作用于整数时,% 是取模运算符,而当第一个运算数是字符串时,% 则是格式化运算符。
文件名和路径
| os模块(operating system) | 提供了操作文件和目录的函数 |
|---|---|
| os.getcwd | 返回当前目录的名称current working directory |
| os.path.abspath | 绝对路径(absolute path) |
| os.path.exists | 检查一个文件或者目录是否存在 |
| os.path.isdir | 检查它是否是一个目录 |
| os.path.isfile | 检查它是否是一个文件 |
| os.listdir | 返回给定目录下的文件列表 |
遍历一个目录,打印所有文件的名字,并且针对其中所有的目录递归的调用自身:
数据库
举个例子,我接下来创建建一个包含图片文件标题的数据库。
| dbm模块 | 提供了一个创建和更新数据库文件的接口 |
|---|---|
| db = dbm.open(‘captions’, ‘c’) | 模式 ‘c’ 代表如果数据库不存在则创建该数据库 |
| db[‘cleese.png’] = ‘Photo of John Cleese.’ | 创建一个新项时,dbm 将更新数据库文件 |
| db[‘cleese.png’] | 访问某个项时,dbm 将读取文件 b’Photo of John Cleese.’ |
| db.close() | 操作后需要关闭文件 |
一些字典方法,例如 keys 和 items ,不适用于数据库对象,但是 for 循环依然适用:
序列化
dbm 的一个限制在于键和值必须是字符串或者字节。
pickle模块 能将几乎所有类型的对象转化为适合在数据库中存储的字符串,以及将那些字符串还原为原来的对象。
你可以使用 pickle 将非字符串对象存储在数据库中。 事实上,这个组合非常常用,已经被封装进了模块 shelve 中。
管道???
编写模块
任何包含 Python 代码的文件,都可以作为模块被导入。作为模块的程序通常写成以下结构:
_name_是一个在程序开始时设置好的内建变量。 如果程序以脚本的形式运行,__name__ 的值为 __main__ ,这时其中的代码将被执行。否则当被作为模块导入时,其中的代码将被跳过。
调试
当你读写文件时,可能会遇到空白带来的问题。内建函数 repr 可以用来解决这个问题。它返回一个该对象的字符串表示。对于空白符号,它将用反斜杠序列表示:
术语表
| 名词 | 定义 |
|---|---|
| 格式化运算符(format operator) | % 读取一个格式化字符串和一个元组,生成一个包含元组中元素的字符串,按照格式化字符串的要求格式化 |
| 格式化字符串(format string) | 一个包含格式化序列的字符串,和格式化运算符一起使用 |
| 格式化序列(format sequence) | 格式化字符串中的一个字符序列,例如%d,指定了一个值的格式 |
| 捕获(catch) | 为了防止程序因为异常而终止,使用 try 和 except 语句来捕捉异常 |
| 管道对象(pipe object) | 一个代表某个正在运行的程序的对象,允许一个 Python 程序去运行命令并得到运行结果 |
第十五章:类和对象
程序员自定义类型
我们已经使用过了许多 Python 的内置类型; 现在我们要定义一个新类型。举个例子,我们来创建一个叫做 Point 的类型,代表二维空间中的一个点(x,y)。
在 Python 中,有几种表示点的方法:
- 我们可以将坐标存储在两个独立的变量,x和y中。
- 我们可以将坐标作为一个列表或者元组的元素存储。
- 我们可以创建一个新类型将点表示为对象。
程序员自定义类型( A programmer-defined type )也被称作类(class)。 定义一个叫做 Point 的类将创建了一个类对象(class object):
类对象就像是一个用来创建对象的工厂。创建一个新对象的过程叫做实例化(instantiation),这个新对象叫做这个类的一个实例(instance)。
属性
你可以使用点标记法向一个实例进行赋值操作:
变量 blank 引用了一个 Point 类,这个类拥有了两个属性。 每个属性都引用了一个浮点数。
矩形
为了描述一个矩形的位置和大小,你需要设计哪些属性呢? 至少有两种可能的设计:
- 你可以指定矩形的一个角(或是中心)、宽度以及长度。
- 你可以指定对角线上的两个角。
这个时候还不能够说明哪个方法优于哪个方法。我们先来实现前者。下面是类的定义:
文档字符串中列出了属性:width 和 height 是数字; corner是一个 Point 对象,代表左下角的那个点。
为了描述一个矩形,你需要实例化一个 Rectangle 对象,并且为它的属性赋值:表达式 box.corner.x 指, 前往 box 所引用的对象,找到叫做 corner 的属性; 然后前往 corner 所引用的对象,找到叫做 x 的属性。

对象图展示了这个对象的状态。 一个对象作为另一个对象的属性叫做嵌套(embedded)。
术语表
| 名词 | 定义 |
|---|---|
| 类(class) | 一种程序员自定义的类型。类定义创建了一个新的类对象 |
| 类对象(class object) | 包含程序员自定义类型的细节信息的对象。类对象可以被用于创建该类型的实例 |
| 实例(instance) | 属于某个类的对象 |
| 实例化(instantiate) | 创建新的对象 |
| 属性(attribute) | 和某个对象相关联的有命名的值 |
| 嵌套对象(embedded object) | 作为另一个对象的属性存储的对象 |
| 浅复制(shallow copy) | 在复制对象内容的时候,只包含嵌套对象的引用,通过 copy 模块的copy函数实现 |
| 深复制(deep copy) | 在复制对象内容的时候,既复制对象属性,也复制所有嵌套对象及其中的所有嵌套对象,由 copy 模块的deepcopy函数实现 |
| 对象图(object diagram) | 展示对象及其属性和属性值的图 |
第十六章:类和函数
术语表
| 名词 | 定义 |
|---|---|
| 原型和补丁(prototype and patch) | 一种开发方案,编写一个程序的初稿,测试,发现错误时修正它们 |
| 设计开发(designed development) | 一种开发方案,需要对问题有更高层次的理解,比增量开发或原型开发更有计划性 |
| 纯函数(pure function) | 一种不修改任何作为参数传入的对象的函数。大部分纯函数是有返回值的(fruitful) |
| 修改器(modifier) | 一种修改一个或多个作为参数传入的对象的函数。大部分修改器没有返回值;即返回 None |
| 函数式编程风格(functional programming style) | 一种程序设计风格,大部分函数为纯函数 |
| 不变式(invariant) | 在程序执行过程中总是为真的条件 |
| 断言语句(assert statement) | 一种检查条件是否满足并在失败的情况下抛出异常的语句 |
第十七章:类和方法
第十九章:进阶小技巧
条件表达式
|
|
列表推导式
|
|
生成器表达式
生成器表达式与列表推导式类似,但是使用的是圆括号,而不是方括号:
any 和 all
|
|
Python还提供了另一个内建函数 all,如果序列中的每个元素均为 True 才会返回 True 。
集合
返回不在 d2 中但在 d1 里的键组成的字典。
计数器
计数器(Counter)类似集合,区别在于如果某个元素出现次数超过一次,计数器就会记录其出现次数。
计数器的行为与字典有很多相似的地方:它们将每个键映射至其出现的次数。
defaultdict?
第二十章:调试
语法错误
- 确保你没有使用 Python 的关键字作为变量名称。
- 检查你在每个复合语句首行的末尾都加了冒号,包括for,while,if,和 def 语句。
- 确保代码中的字符串都有匹配地引号。确保所有的引号都是“直引号”,而不是“花引号”。
- 如果你有带三重引号的多行字符串,确保你正确地结束了字符串。一个没有结束的字符串会在程序的末尾产生
invalid token错误,或者它会把剩下的程序看作字符串的一部分,直到遇到下一个字符串。 - 一个没有关闭的操作符
(, { 以及 [使得 Python 把下一行继续看作当前语句的一部分。通常下一行会马上提示错误消息。 - 检查条件语句里面的 == 是不是写成了 = 。
- 确保每行的缩进是符合要求。Python 能够处理空格和制表符,但是如果混用则会出错。避免该问题的最好方法是使用一个了解 Python 语法、能够产生一致缩进的纯文本编辑器。
- 如果代码中包含有非ASCII字符串(包括字符串和注释),可能会出错,尽管 Python 3 一般能处理非ASCII字符串。从网页或其他源粘贴文本时,要特别注意。
第二十一章:算法分析
算法分析的实际目的是预测不同算法的性能,用于指导设计决策。
增长量级
假设你已经分析了两个算法,并能用输入计算量的规模表示它们的运行时间: 若算法 A 用 100n+1 步解决一个规模为 n 的问题;而算法 B 用 n^2+n+1 步。
下表列出了这些算法对于不同问题规模的运行时间:
| Input | Run time of | Run time of |
|---|---|---|
| size | Algorithm A | Algorithm B |
| 10 | 1001 | 111 |
| 100 | 10 001 | 10 101 |
| 1 000 | 100 001 | 1 001 001 |
| 10 000 | 1 000 001 | >10^10 |
增长量级(order of growth)是一个函数集合,集合中函数的增长行为被认为是相当的。 例如2n、100n和n+1属于相同的增长量级,可用 大O符号(Big-Oh notation) 写成O(n), 而且常被称作 线性级 (linear),因为集合中的每个函数随着n线性增长。
下表列出了算法分析中最通常的一些增长量级,按照运行效率从高到低排列 。
| Order of Growth | Name | 名称 |
|---|---|---|
| O(1) | constant | 常数级 |
| O(logbn) | logarithmic | 对数级 |
| O(n) | linear | 线性级 |
| O(nlogbn) | linearithmic | 线性对数级 |
| O(n2) | quadratic | 二次方级 |
| O(n3) | cubic | 三次方级 |
| O(cn) | exponential | 指数级 |
Python基本运算操作分析
在 Python 中,大部分算术运算的开销是常数级的;
索引操作 — 在序列或字典中读写元素 — 的增长量级也是常数级的,和数据结构的大小无关。
搜索算法分析
搜索 (search)算法,接受一个集合以及一个目标项,并判断该目标项是否在集合中,通常返回目标的索引值。最坏的情况下, 它不得不遍历全部集合,所以运行时间是线性的。
序列的 in 操作符使用线性搜索;字符串方法 find 和 count 也使用线性搜索。
如果元素在序列中是排序好的,你可以用 二分搜素 (bisection search) ,它的增长量级是 O(logn) 。 二分搜索比线性搜索快很多,但是它要求已排序的序列,因此使用时需要做额外的工作。

